It’s Friday at 3:00 PM. Do you push the button?
Your lead developer has a feature ready that could close a major Q4 deal. Your SysAdmin is staring at a dashboard that’s already flashing red warnings. Do you push the button?
This conflict isn’t new, but in 2026, the stakes are different. We aren’t just talking about frustrated users anymore; we are talking about a measurable financial leak. With distributed microservices generated by AI coding assistants, complexity has exploded. Relying on “hope” and manual heroics to keep production alive is no longer a strategy—it’s a liability.
Site Reliability Engineering (SRE) is the answer to this deadlock. It’s not a rebrand of the SysAdmin role. It is a fundamental shift where we stop treating operations as a manual task and start treating it as a software problem. SRE replaces anxiety with math, and gatekeeping with automated guardrails.
If you want to scale your infrastructure without scaling your headcount linearly, this is your blueprint.
Key takeaways in 60 seconds:
- Observability > Monitoring: Monitoring tells you that the server is down. Observability tells you why, even if it’s a failure mode you’ve never seen before. In 2026, this distinction cuts Mean Time to Resolution (MTTR) by 60%.
- The Error Budget strategy: 100% uptime is expensive and often impossible. SRE introduces the Error Budget, a “credit card” for failure. As long as you have credit, you ship features. If you max out the card, you freeze deployments to pay down debt.
- The “50% rule” on Toil: If your engineers spend more than 50% of their time on manual grunt work (toil), you’re burning money. The other 50% must be spent coding automation to remove that work forever.
- Data over gut feelings: No more arguing in meetings. We use SLIs, SLOs, and SLAs to make objective decisions about reliability.
- The cost of inaction: The benchmark for 2025 shows the cost of downtime for B2B platforms hitting $300,000 per hour. SRE is defensive armor for your P&L.
What is Site Reliability Engineering (SRE)?
At its core, SRE is what happens when you treat operations as a software engineering problem. The term originated at Google, but today it’s the standard for anyone running complex systems.
Think of the traditional “SysAdmin” model. Stability usually relied on humans running scripts, manually restarting pods, or staring at graphs. It works fine until you scale. To manage 10x more servers, you needed 10x more people.
SRE breaks that equation. An SRE engineer doesn’t just fix a recurring issue; they write code to automate the fix or re-architect the system to heal itself. The goal is simple: build systems that are reliable enough to run without a human babysitter.
The SRE alphabet: SLI, SLO, and SLA
You can’t manage what you don’t measure. But “Uptime” is a vanity metric. SRE uses a precise vocabulary to translate engineering reality into business expectations.
1. Service Level Indicator (SLI) – “The Real-Time Truth”
This is the raw data. It’s the direct reading from the dashboard.
- What it measures: Latency, error rate, throughput.
- Example: “The 99th percentile latency of /checkout over the last 5 minutes.”
2. Service Level Objective (SLO) – “The Engineering Target”
This is the internal speed limit. It’s the line in the sand where “reliable enough” meets “too risky.”
- The rule: The SLO is strictly for the team. It is tighter than the SLA to give you a buffer.
- Example: “99.9% of requests will be served in under 300ms.”
- Strategic insight: If you hit your SLO, you have permission to develop and allow yourself to break a few things. If you miss it, you stop, and focus on stability instead.
3. Service Level Agreement (SLA) – “The Financial Promise”
This is the contract with the customer (and the lawyers). It dictates the penalty for failure.
- Context: If you breach the SLO, the team wakes up. If you breach the SLA, the CFO wakes up.
- Example: “If availability drops below 99.0%, we owe the customer a 20% credit.”
| Metric | Audience | Purpose | Threshold Example |
| SLI | Engineers | Diagnostic / Monitoring | 215ms latency |
| SLO | Product Owners / SRE | Internal Goal / Prioritization | < 300ms (99.9%) |
| SLA | Customers / Legal | Contractual Obligation | < 500ms (99.0%) |
DevOps vs. SRE: The implementation matrix
There’s a misconception that SRE competes with DevOps. They don’t. They are symbiotic. The best way to frame it? “Class SRE implements Interface DevOps.”
- DevOps is the culture. It asks: “Why don’t Dev and Ops talk to each other?”
- SRE is the prescriptive implementation. It asks: “How do we measure that conversation, and exactly how many errors are allowed per release?”
Strategic Comparison Table: DevOps vs. SRE
| Feature | DevOps (The Culture) | SRE (The Implementation) |
| Primary Goal | Accelerate Software Delivery (Time-to-Market). | Balance Velocity with System Stability. |
| Approach to Failure | “Fail fast, recover faster.” | “Failure is inevitable; manage it with Error Budgets.” |
| Responsibility | Shared ownership across the entire SDLC. | Specialized engineers focused on system architecture & automation. |
| Key Metrics | Deployment Frequency, Lead Time for Changes. | SLO Availability, Error Budget Remaining, Toil %. |
| Tooling Focus | CI/CD Pipelines (e.g., Jenkins, GitLab). | Observability & Chaos Engineering (e.g., Datadog, Gremlin). |
1. The economics of reliability: The Error Budget

The single most transformative concept in SRE is the Error Budget. It creates a common currency for Product and Engineering.
The premise: Aiming for 100% reliability is financially wasteful. The cost to go from 99.99% to 99.999% is massive, and your user—who is on spotty 5G—won’t even notice the difference.
The mechanism: The Error Budget is the inverse of your SLO.
- If your SLO is 99.9%, your Error Budget is 0.1%.
- In a month, that gives you 43 minutes of allowed downtime.
The governance rule:
- Budget surplus: If you have budget remaining, developers are free to launch risky features, perform A/B tests, and push updates rapidly.
- Budget depleted: If the budget is exhausted (due to outages or instability), all feature deployments are frozen. The engineering team pivots 100% of their effort to reliability fixes, automation, and tech debt reduction until the budget resets.
This mechanism removes subjective arguments from release meetings. The data decides whether you ship or stabilize.
2. Eliminating the culture of fear: Blameless postmortems

In many IT shops, an outage triggers a witch hunt. “Who touched the config?” This creates a culture of fear where engineers hide issues. SRE mandates the Blameless Postmortem.
- The rule: You cannot fire or punish someone for a mistake made in good faith.
- The logic: If a human could crash production by typing a wrong command, the system was designed poorly, not the human.
- The outcome: We use the “5 Whys” to find the root cause and build automated guardrails so it never happens again.
Tactics & methods: The 4 pillars of modern SRE
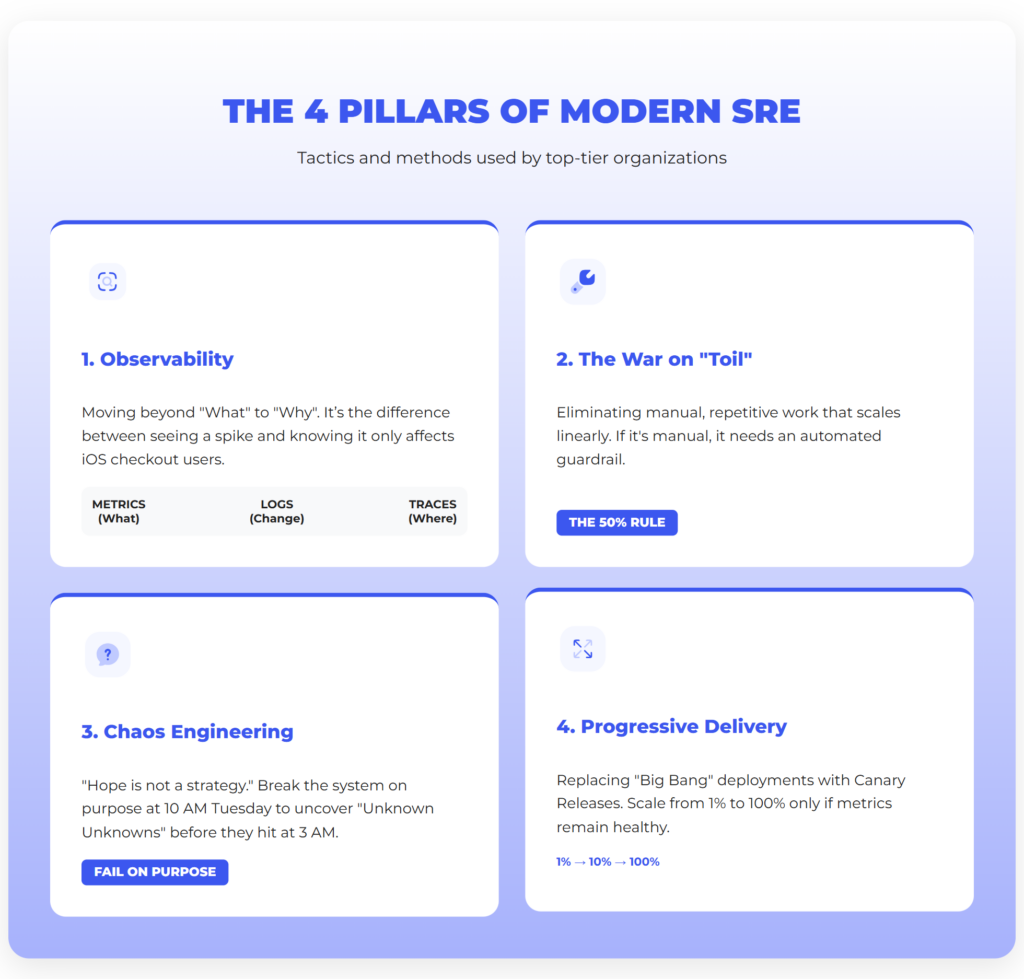
How do top-tier organizations actually do this? They don’t rely on luck. They build on four pillars.
Pillar 1: From monitoring to observability
In 2026, traditional monitoring is obsolete. Monitoring tells you “CPU is at 99%.” Observability lets you ask “Why is CPU at 99% only for iOS users on the checkout page?”
It relies on the Trinity of Data:
- Metrics: “What is happening?”
- Logs: “What changed?”
- Traces: “Where did the request die?”
Pillar 2: The war on “Toil”
SRE defines Toil as work that is manual, repetitive, and scales linearly with growth (like manually clearing disk space).
- The 50% rule: Google’s handbook is strict here. Engineers should spend max 50% of their time on Ops work (Toil). The other 50% must be spent coding automation to eliminate that Toil. If you cross the line, you hire more people or stop features.
Pillar 3: Chaos engineering
“Hope is not a strategy.” You can’t know if your system is resilient until it breaks. Chaos Engineering is the practice of breaking it on purpose.
- The method: Instead of waiting for Amazon to have an outage at 3 AM, you use tools like Gremlin to simulate a server failure at 10 AM on a Tuesday, when everyone is caffeinated.
- The goal: Uncover “Unknown Unknowns”—like finding out your “stateless” app crashes if the Redis cache blips.
Pillar 4: Progressive delivery
The days of “Big Bang” deployments are over. SRE mandates Progressive Delivery via Canary Releases:
- Deploy to 1% of traffic (the “Canary”).
- If metrics look good, scale to 10%, then 100%.
- If metrics spike, automatically rollback. This turns a potential PR disaster into a minor statistic that 99% of your users never saw.
The “Tooling Trap”: Why buying Datadog doesn’t make you an SRE organization
We see this pattern constantly: The “Tool-First Fallacy.” Companies buy expensive licenses for Datadog or Dynatrace, install the agents, and expect magic.
Our Point of View: Reliability isn’t software you buy; it’s a cultural behavior. If you have the best dashboards in the world, but your Product Owner refuses to freeze deployments when the Error Budget is empty, you don’t have SRE. You just have expensive monitoring for your chaos.
True SRE requires a handshake:
- Business acknowledges that 100% uptime is impossible.
- Engineering commits to maximizing velocity within those limits.
Our Expert Voice:
“SRE is often misunderstood as ‘hiring people to wake up at 3 AM so developers don’t have to.’ That is wrong. The goal of SRE is to design systems that don’t wake anyone up at 3 AM. If your SRE team is spending 90% of their time fixing incidents manually, you haven’t adopted SRE, you have just rebranded your burnout. Real reliability comes from the uncomfortable discipline of stopping production when your math tells you the system is too fragile.” — Gerard Stańczak, CEO at Relout
The ROI of “No” The most valuable word an SRE can say is “No.”
- “No, we cannot deploy this Friday.”
- “No, we cannot skip the load test.” This friction is healthy. It forces the organization to monetize stability.
Tools & Technology – The 2026 SRE stack
There is no “Golden Hammer,” but at Relout, we rely on a battle-tested stack.
1. Observability & Monitoring
- Datadog: The enterprise standard. It unifies everything in one pane of glass. Best for enterprises who want AI-driven anomaly detection but as with any enterprise, be wary of hidden costs.
- Prometheus + Grafana: The Open Source standard. Best for Kubernetes-native teams who want full control and no vendor lock-in.
- Dynatrace: The “AI-First” competitor. Great for complex hybrid clouds where manual correlation is a nightmare.
2. Incident Management
- PagerDuty: The undisputed leader. It handles the schedules and wakes up the right person (and escalates if they don’t answer).
- Opsgenie (Atlassian) or Compass: Strong alternative if you live in Jira. Seamless integration for postmortems.
3. Error Tracking
- Sentry: Essential for devs. It shows the exact line of code that caused the crash. It helps developers “own” their code quality.
4. Chaos Engineering
- Gremlin: “Failure as a Service.” It safely injects failure to verify your automated failovers actually work. In 2026, this is becoming a compliance requirement in Fintech.
The 2026 SRE market report

Decisions in IT should be based on metrics, not intuition. Below are the critical data points defining the Site Reliability Engineering landscape in 2026. Use these figures to benchmark your organization and justify your budget allocation.
1. The Financial Impact of Instability
- According to the Information Technology Intelligence Consulting (ITIC) 2024 Hourly Cost of Downtime Report, over 90% of large and medium-sized enterprises reported that a single hour of unplanned downtime costs their business more than $300,000, and around 41% of respondents indicated costs of $1 million to $5 million or more per hour of operational system unavailability. (ITIC 2024 Report)
- Additionally, the New Relic 2024 Observability Forecast shows that downtime in high-impact systems can cost up to approximately $1.9 million per hour. (New Relic 2024 Forecast)”
- 15x ROI: Organizations that successfully implement SRE practices report a Return on Investment of approximately 15:1. Every dollar spent on automation and proactive reliability prevents $15 in future operational costs and outage mitigation.
2. Operational Efficiency (Speed of Recovery)
- According to DORA’s State of DevOps research, elite performing teams typically recover from service failures in less than an hour, whereas low performers may take days or weeks, reflecting the significant impact that advanced practices like observability and automated recovery can have on Mean Time to Recover (MTTR).
- 50% Less Time on “Firefighting”: Mature SRE organizations adhere strictly to the “50% Toil Cap.” This results in engineers spending half their week creating value (coding) rather than maintaining the status quo.
3. The Human Factor: Retention & Burnout
- 40% Lower Churn: High turnover in IT is often driven by “On-Call Fatigue.” Companies implementing Blameless Postmortems and Human-Centric On-Call Schedules see a 40% reduction in staff turnover.
- Developer Satisfaction: 89% of developers prefer working in environments with defined Error Budgets because it provides clear “Safety Rails” for deployment, eliminating the fear of breaking production.
4. Future Adoption Trends
- The market for chaos engineering tools is projected to grow strongly over the coming decade as organizations adopt resilience testing practices to improve system reliability in cloud‑native and DevOps environments
FAQ: SRE Knowledge Base
Below are the most frequent technical and strategic questions we encounter during SRE implementations.
1. Is SRE viable for small startups, or is it only for enterprises? SRE is a mindset, not a headcount. A startup doesn’t need a full “SRE Team,” but it needs one engineer (or a shared role) who enforces the “50% Toil” rule and works on observability. Implementing SRE early prevents technical debt from killing your velocity later.
2. What is the difference between “Embedded” and “Centralized” SRE teams?
- Centralized: A consulting team for the whole company. Good for standards, risk of silos.
- Embedded: SREs sit inside product squads. Good for speed, risk of isolation.
- Recommendation: Start centralized to build the platform, then embed as you scale.
3. Should SREs be responsible for writing feature code? Generally, no. But SREs must write code. Their code builds the tooling and automation that allows developers to ship features safely. If an SRE is only closing Jira tickets, they aren’t doing SRE.
4. How do we implement SRE for a legacy monolith? You don’t need microservices. Start by defining SLIs for the monolith’s key endpoints (Login, Checkout). Use the Error Budget to argue for refactoring the most unstable modules first.
5. How do I define SLIs for a REST API? Focus on the Golden Signals: Availability (success rate), Latency (speed), and Throughput. Don’t measure CPU usage as an SLI; measure the user experience, not the machine pain.
6. What happens when the Error Budget is exhausted? The policy triggers.
- Freeze: All non-critical features stop.
- Focus: The sprint shifts to reliability tasks.
- Reset: Features resume only when stability is proven or the budget period resets.
Summary: Reliability is the most underrated feature
You now understand that Site Reliability Engineering isn’t about hiring better SysAdmins. It is a fundamental shift in how your organization values risk. In 2026, the winners aren’t those who break things fast, but those who fix them faster than the competition.
Reliability is a feature. If your system is down, your features do not exist.
The “Fork in the Road”: You have two options
Now that you know the math, you have a choice:
Option A: The “Hero” path
- You continue to rely on individual heroism to keep servers running.
- Your best engineers burn out from 3 AM pages and eventually leave.
- You pay the “hidden tax” of downtime every week.
Option B: The SRE path
- You implement Error Budgets to align Business and Tech.
- You invest in automation to cap Toil at 50%.
- Your system heals itself, and your team sleeps through the night.
Ready to stop firefighting?
You don’t have to build Google-scale infrastructure overnight. You just need to start measuring the right things.